SUBMISSION GUIDELINES
The upper bound of the model size is 2MB. (storage size of the model file)
The upper bound of computational complexity is 100MFLOPs. (If your model is trained by PyTorch, THOP is recommended to compute the complexity.)
To improve the accuracy on masked-face scenarios, the model ensemble strategy is allowed. However, you should know that the limitations of model size and complexity are based on all the models you submit. Besides, if your model executes multiple times, the model size and complexity will be multiplied.
During the validation phase, each team could send a compressed file (
.ziponly), consisting of 2,000 landmark files (.txt) of the validation set, to fllc3_icme@163.com. We will return the performance to the participants by updating the leaderboard. Each file (.txt) should contain the number of key points along with the predicted coordinates for each point. An example is shown in Fig. 1. The coordinates of the top left corner is [0, 0], where the first number refers to horizontal coordinate and the second number refers to vertical coordinate. If multiple faces are detected by the face detector, please just choose the one which has the biggest IOU with the provided bounding box as the output. Note that each team can only submit once a day.The participants should strictly name their e-mail subject in
teamname_FLL3submission format and name Attachment inteamname_mmddyyyy.zip format. For instance, my team's name is Giant and it's February 24, 2021 today. So the subject and attachment of e-mails should be Giant_FLL3submission and Giant_02242021.zip, respectively.During the test phase, participants need to submit their model and paper in a week. It will be used for the final evaluation. Specifically, all the training materials including codes, models, experiment environments (
pip freeze > ./requirements.txt), external datasets, and technical reports need to be sent to us before April 7, 2021. The technical should clearly describe how to run the model and introduce the algorithms, experimental configurations, training detail.Participants should also submit their results on the validation set, since we need to ensure the results of our execution are consistent with yours, confirming the test phase is correct. Any team whose results we cannot reproduce or whose computational complexity or model size cannot satisfy the requirements will be disqualified.
We highly recommend every team submit their paper. Once accepted, the paper will be published at International Conference on Multimedia and Expo Workshop (ICMEW 2021). The paper template is now available on ICME's official website. You can use the current results on the validation set to write any experiments or conclusions. We'll release the final results to you on April 30, 2020. The Camera-ready paper submission deadline will be May 7, 2021, so you still have one week to polish your paper.
The test set contains 2000 virtual-masked images and 2000 in-the-wild real-masked images, which has the same names and file structure as validation set. Typically, your test code or script should access three parameters. Parameter1 is image directory, Parameter2 is bounding box directory, and Parameter3 is predicted landmark directory.
For example,python test.py ../test/picture_mask ../test/bbox ../test/landmark_teamname
If you are using your own face detectors, the parameter2 is redundant. The details are shown in the following table.After final submission, the test results will be uniformly released to the participants on April 30th and the ranking will be announced, too.

Fig. 1 Example of the landmark file.
Important for model and paper submission
| parameters | description | content |
| parameter1 | image directory | 2000 masked-face images (.jpg format) |
| parameter2(optional) | bounding box directory | 2000 masked-face images' bounding box folder(.txt format) |
| parameter3 | predicted landmark directory | 2000 predicted 106-points landmark(.txt format) |
Evaluation criteria
Submissions will be evaluated on the area-under-the-curve (AUC) from the cumulative errors distribution (CED) curves.
We will score on the arithmetic mean of the AUC. Besides, further statistics from the CED curves such as the failure rate and average normalized mean error (NME) will also be returned to the participants for inclusion in their papers.
The cumulative curve corresponding to the percentage of test images of which the error is less than a threshold ⍺ will be produced. The AUC is the area under the CED curve calculated up to the threshold ⍺, then divided by that threshold. We set the variable ⍺ to be 0.08.
Similarly, we regard each image with a Normalized Mean Error (NME) larger than α as a failure. NME is computed as:
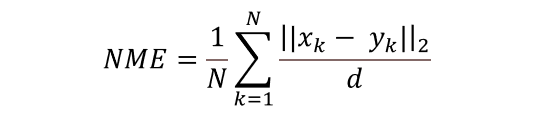
where "x" denotes the ground truth landmarks for a given face, "y" denotes the corresponding prediction and "d" is computed as
 . Here, widthbbox and heightbbox
are the width and height of the enclosing rectangle of the ground truth landmarks.
. Here, widthbbox and heightbbox
are the width and height of the enclosing rectangle of the ground truth landmarks.
constraint:
Due to the invisibility of the nose and mouth under the mask, there are inevitable diversities when people predict the facial landmarks in these areas. For fairness, we decide to ignore some abnormal points when we do evaluations on validation & test sets.
-
In the nose area, we ignore points on the wing of nose (57-60, 62-65), and only leverage the points (52, 53, 54, 55, 56, 61, 66) for evaluation.
-
In the mouth area, we only consider point 88. Usually, mask will cover the whole mouth, and it is pretty hard to predict the shape of mouth due to the individual differences and expression variations. Thus, we only take point 88 into account when computing the NME.
-
In the eye and eyebrow area, it is visible. So, we take all the points into account.
-
For face profile, sometimes it is challengeable but crucial to differentiate different people. Therefore, we take all these points, from 1 to 33, into account and ask for high accuracy.

Figure2: The key-points used for our annotations