Dataset Description
The structure of files that competitors can get is shown below. The file picture_mask means face images covered by virtual masks. The algorithm is publicly opened in FaceX-Zoo[3].
Besides, we use a face parsing model trained on Lapa[2] dataset to deal with facial occlusion.
The file bbox means bounding box, which is obtained by our detector for training/validation sets. You are allowed to employ your own face detectors.
We also allow participants to use their own mask-add algorithms and additional images for training.
However, once using, it is necessary to explain in detail
what additional data and mask-add methods are when you submit the model and paper.
Meanwhile, you need to send the addition data to fllc3_icme@163.com, so that we can reproduce and check the results.

Figure1: Structure of file
Training dataset:
We collect an incremental dataset named JD-landmark-mask. Base on the face images in JD-landmark[1, 4-10] dataset, we provide the virtual-masked face images by utilizing our virtual mask-add algorithm[3]. This dataset, containing about 20,386 faces, is accessible to the participants (with landmark annotations). participants should train their model on the masked pictures. The images and landmarks will be released on March 4, 2021.

Figure2: Examples of training dataset
Validation dataset:
It consists of 2000 virtual-masked images which are generated
by the same method as the training dataset. The participants’
models will be evaluated on this set before the final evaluation.
The masked images without ground truth will be released on March 4, 2021, simultaneously.
During the validation phase (March 7 - March 31, 2021), participants could send the results on the validation set to us,
and we will return the performance to the participants by updating the leaderboard. Each team could only submit once a day.
For more information, please refer to submission guidelines.

Figure2: Examples of validation dataset
Test dataset:
It contains 2000 virtual-masked images and 2000 in-the-wild real-masked images
which are collected from the internet.
It will be used for the final evaluation.
To prevent cheating on the test set, the test images will not be released to participants.
And participants need to submit their model and paper within a week, from April 1 - April 7.
Specifically, all the training materials including codes, models, and technical reports need to be sent to us before April 7, 2021.
-
Note!:
the test dataset is blind to participants
throughout the whole competition.There are inevitable domain gaps between
virtual-masked and real-masked face images. Besides, the real-masked face images,
which contain more noised, blurry, and low-resolution images,
are more challenging than the virtual-masked face images.
There are some examples below. For privacy reasons, We temporarily blur the real-masked faces.
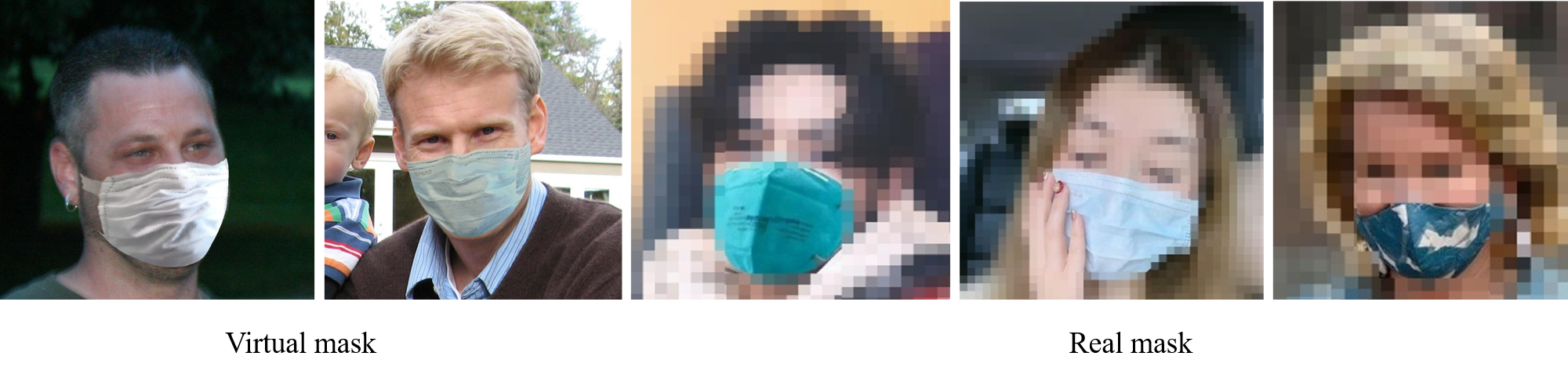
Figure3: Examples of test dataset
commitment
The dataset is available for this grand challenge only.
You agree not to reproduce, duplicate, copy, sell, trade, resell or exploit for any commercial purposes, any portion of the images and any portion of derived data.
You agree not to further copy, publish or distribute any portion of annotations of the dataset. Except, for internal use at a single site within the same organization it is allowed to make copies of the dataset.
The authors acknowledge that if they decide to submit, the resulting curve might be used by the organizers in any related visualizations/results. The authors are prohibited from sharing the results with other contesting teams.
We reserve the right to terminate your access to the dataset at any time.
You will be responsible for the consequences if violated.
citation
Please cite our paper, if you want to use the dataset.
[1] Y. Liu, H. Shen, Y. Si, X. Wang, X. Zhu, H. Shi et al. Grand challenge of 106-point facial landmark localization. In ICMEW, 2019.
[2] Y. Liu, H. Shi, H. Shen, Y. Si, X. Wang, T. Mei. A New Dataset and Boundary-Attention Semantic Segmentation for Face Parsing. In AAAI, 2020.
[3] M. Xiang, Y. Liu, T. Liao, X. Zhu, C. Yang, W. Liu, H. Shi. The 3rd Grand Challenge of Lightweight 106-Point Facial Landmark Localization on Masked Faces. In ICMEW, 2021.
[4] J. Wang, Y. Liu, Y. Hu, H. Shi, T. Mei. FaceX-Zoo: A PyTorch Toolbox for Face Recognition. In arXiv, 2021.
reference
[4] C. Sagonas, G. Tzimiropoulos, S. Zafeiriou, and M. Pantic. 300 faces in-the-wild challenge: The first facial landmark localization Challenge. In ICCVW, 2013.
[5] C. Sagonas, E. Antonakos, G. Tzimiropoulos, S. Zafeiriou, and M. Pantic. 300 faces in-the-wild challenge: Database and results. In IVC, 2016.
[6] Belhumeur, P., Jacobs, D., Kriegman, D., Kumar, N. Localizing parts of faces using a consensus of exemplars. In Computer Vision and Pattern Recognition. In CVPR, 2011.
[7] X. Zhu, D. Ramanan. Face detection, pose estimation and landmark localization in the wild. In CVPR, 2012.
[8] Vuong Le, Jonathan Brandt, Zhe Lin, Lubomir Boudev, Thomas S. Huang. Interactive facial feature localization. In ECCV, 2012.
[9] C. Sagonas, G. Tzimiropoulos, S. Zafeiriou, and M. Pantic. A semi-automatic methodology for facial landmark annotation. In CVPR, 2013.
[10] I. Kemelmacher-Shlizerman, S. M. Seitz, D. Miller, and E. Brossard. The megaface benchmark: 1 million faces for recognition at scale. In CVPR, 2016.